
Помогнете на развитието на сайта, споделяйки статията с приятели!
 Поздрави на всички читатели на блога!
Поздрави на всички читатели на блога!
Мисля, че тези, които често работят на компютър (не играе, т.е. работи), трябваше да се справят с текстовото разпознаване. Е, например, сте сканирали пасаж от книгата и сега трябва да вмъкнете тази част в документа. Но сканираният документ е картина и имаме нужда от текст - за това, тогава са необходими специални програми и онлайн услуги за разпознаване на текст от снимки.
За програмата за признаване вече написах в предишни публикации:
- сканиране на текст и разпознаване в FineReader (платена програма);
- работа в аналоговия FineReader - CuneiForm (безплатна програма).
В същата статия бих искал да се съсредоточа върху онлайн услугите за разпознаване на текст. В края на краищата, ако трябва бързо да получите текста с 1-2 снимки - няма смисъл да се притеснявате с инсталирането на различни програми …
Важно! Качеството на разпознаване (броят на грешките, четливостта и т.н.) зависи до голяма степен от оригиналното качество на картината. Ето защо, когато сканирате (фотографиране и т.н.), изберете качеството възможно най-високо. В повечето случаи качеството на 300-400 dpi ще бъде достатъчно (dpi е параметър, характеризиращ качеството на картината.) При настройките на почти всички скенери този параметър обикновено е показан.
Онлайн услуги
За да покажа работата на услугите, направих снимка на една от моите статии. Тази екранна снимка ще бъде изтеглена до всички описани по-долу услуги.
1) http://www.ocrconvert.com/
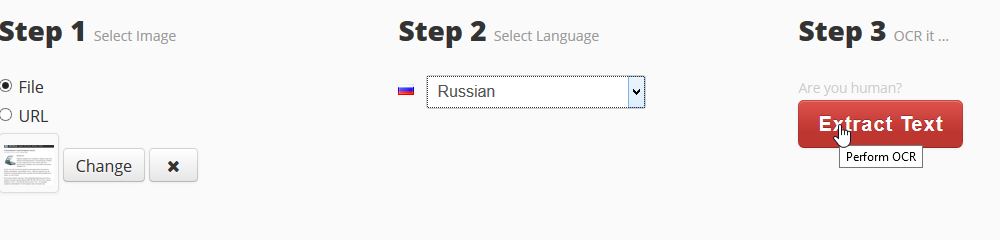
Харесва ми тази услуга много заради нейната простота. Сайтът обаче също е английски, но добре работи и с руски. Не е необходимо да се регистрирате. За да започнете разпознаването, трябва да направите три действия:
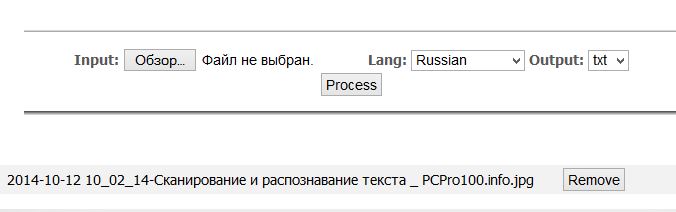
- качване на изображението;
- изберете езика на текста в снимката;
- Натиснете бутона за разпознаване на разпознаване.
Поддържани формати: PDF, GIF, BMP, JPEG.
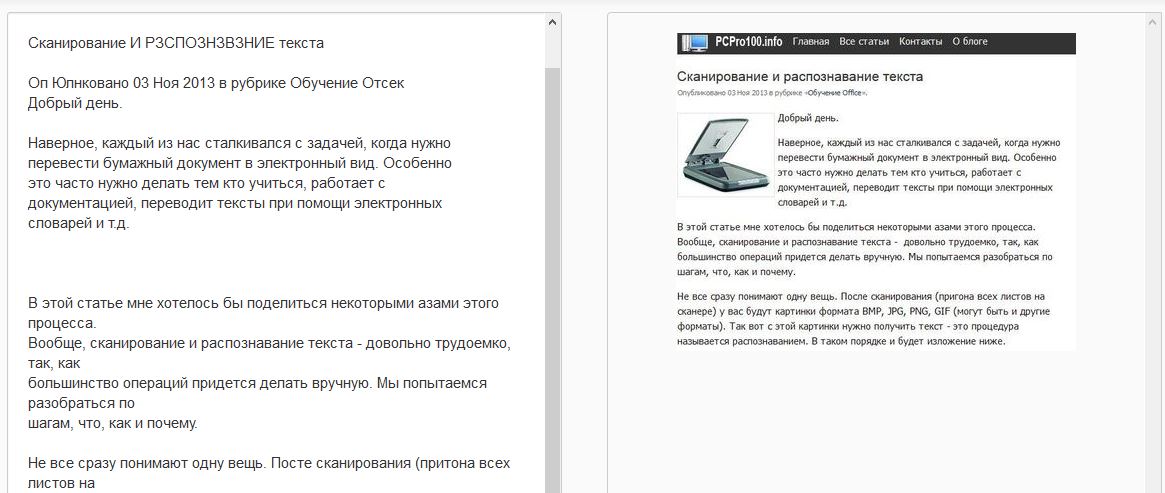
Резултатът е показан по-долу на снимката. Трябва да кажа, че текстът е добре познат. Освен това много бързо - чаках буквално 5-10 секунди.

2) http://www.i2ocr.com/

Тази услуга работи по същия начин като горепосочената. Тук също трябва да изтеглите файла, да изберете езика за разпознаване и да кликнете върху бутона за извличане на текст. Услугата е много бърза: 5-6 сек. за една страница.
Поддържа формати: TIF, JPEG, PNG, BMP, GIF, PBM, PGM, PPM.
Резултатът от тази онлайн услуга е много по-удобен: веднага виждате два прозореца - първият е резултат от разпознаването, а вторият - оригиналното изображение. Ето защо е достатъчно лесно да направите редакции в хода на редактирането. Между другото, не е необходимо да се регистрирате за услугата.
3) http://www.newocr.com/

Тази услуга е уникална по няколко начина. Първо, той поддържа формат "newfangled" DJVU (между другото пълният списък с формати: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu). На второ място, той поддържа избора на текстови области в картината. Това е много полезно, когато имате в картината не само текстови области, но и графики, които не е нужно да разпознавате.
Качеството на разпознаване е над средното, не е необходимо да се регистрирате.
4) http://www.free-ocr.com/
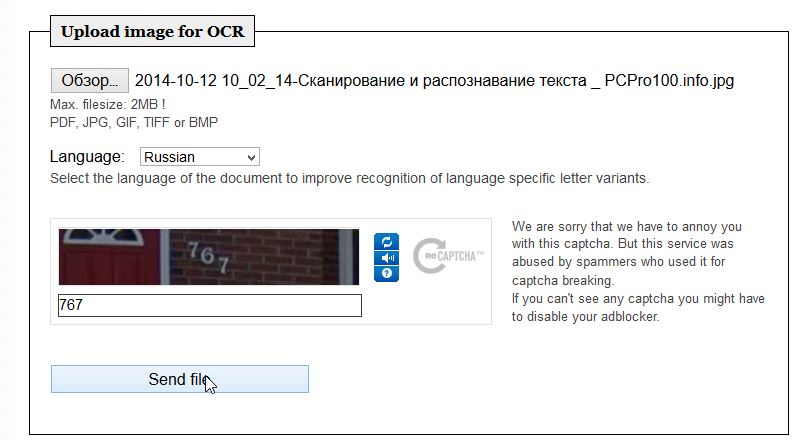
Много проста услуга за разпознаване: изтегляне на изображението, определяне на езика, въвеждане на captcha (между другото, единствената услуга в тази статия, където трябва да се направи) и натиснете бутона, за да преведете изображението в текст. Всъщност всичко!
Поддържани формати: PDF, JPG, GIF, TIFF, BMP.
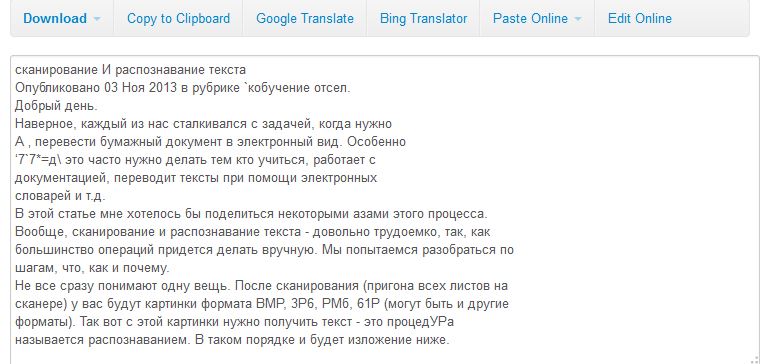
Резултатът от разпознаването е средно. Има грешки, но няма много от тях. Ако обаче качеството на оригиналния екранна снимка би било по-високо - грешките биха били с порядък по-малък.

PS
Това е всичко за днес. Ако знаете по-интересни услуги за разпознаване на текст - споделете в коментарите, ще бъда благодарен. Едно условие: желателно е да не се регистрира и услугата да е безплатна.
Всичко най-хубаво!